[STUDY18] Filebeat → Logstash → ES + RDBMS 실습
피사에서 로그스태쉬에 관하여 배웠어요.
저는 Filebeat → Logstash → Elasticsearch / RDBMS 패턴으로 로그를 수집하고 가공, 저장하는 로그 파이프라인 아키텍처를 선택했어요.
1. 각 구성요소의 역할, 왜 필요한지적어볼게요.
⁉️FileBeat?
이건 로그 수집 에이전트에요. 서버에 생성되는 로그 파일을 실시간으로 감시하고,
새로 추가되는 로그 라인을 중앙 수집 시스템(logstash 또는 es)로 전송하는 경량 에이전트입니다.
저번에 우리카드데이터를 받았는데 1.5기가였습니다. 그걸 es에 올리기엔 100MB가 한정적이라 파일을 잘라서 올렸는데, 이때 로그스태쉬를 쓰면 좋았을 것 같네요.
핵심역할?
WAS,WEB, DB서버의 로그 파일을 감시하고 이벤트 단위로 전송합니다.
왜 필요한가?
애플리케이션 서버마다 직접 ES로 로그를 보내면 관리가 어려워요. 그리고 로그 파일을 주기적으로 scp,cron으로 수집하는 방식은 비효율적입니다. 그래서 Filebeat는 로그 생성 서버에 상주하며 자동으로 수집합니다.
하지 않는 것 ?
복잡한 데이터 가공 / 비지니스 로직 / 데이터 저장은 하지 않고 정확히 운반 역할만 합니다!
⁉️Logstash?
이건 수집된 로그를 가공, 정규화, 분기처리하는 중앙 처리 시스템입니다.
핵심역할?
로그 파싱 , 필드 분리 및 타입 변환, 불필요한 로그 제거, 목적지별 라우팅등을 합니다.
왜 필요한가?
filebeat는 가볍게 설계되어있어복잡한 가공을 하지 않아요. 그런데 실제 분석을 위해서는
IP를 client IP로 바꾼다던가, 시간 문자열을 timestamp로 바꾼다던가, HTTP로그를 부리한다던가의 작업이필요합니다
어떻게 동작하는가?
input- filter- output의 형태로 작동합니다.
filebeat, kafka, tcp/udp등의 input이 들어오면, ㅣ필터링하고, es나 rdbms 파일등으로 내보냅니다.
⁉️Elastic Search?
이건 대용량 로그 데이터를 실시간으로 검색/집계/시각화 하기 위한 분산 검색 엔진이에요.
핵심역할? 로그검색, 집계 , kibana로 시각화 한다던가 하는 역할을 합니다.
분석 조회 모니터링할땐 es를 쓰고 rdbms는 저장할때 써요.
RDBM vs Elasticsearch
| 대용량 로그 | ❌ | ⭕ |
| 전문 검색 | ❌ | ⭕ |
| 실시간 집계 | 느림 | 매우 빠름 |
| 스키마 유연성 | 낮음 | 높음 |
2. 실습 아키텍처
filebeat - logstash - es+rdbms 순서대로 진행하며, oracle db를 사용합니다.
3. 실습
1. 로그 기록을 남깁니다.
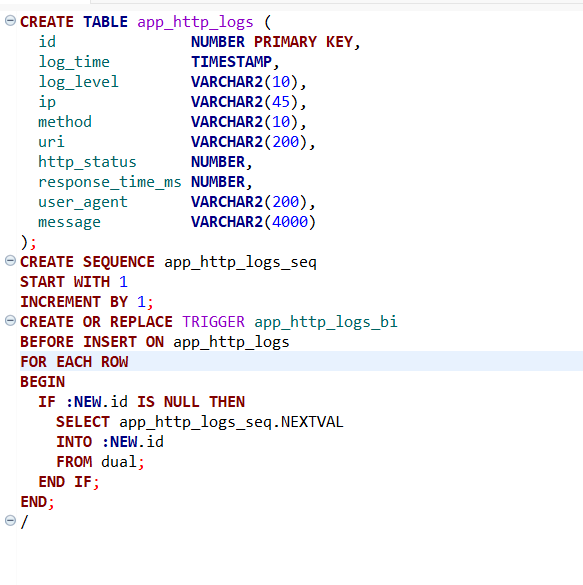
2. db에 로그데이터 테이블을 만들어줍니다.with dbeaver
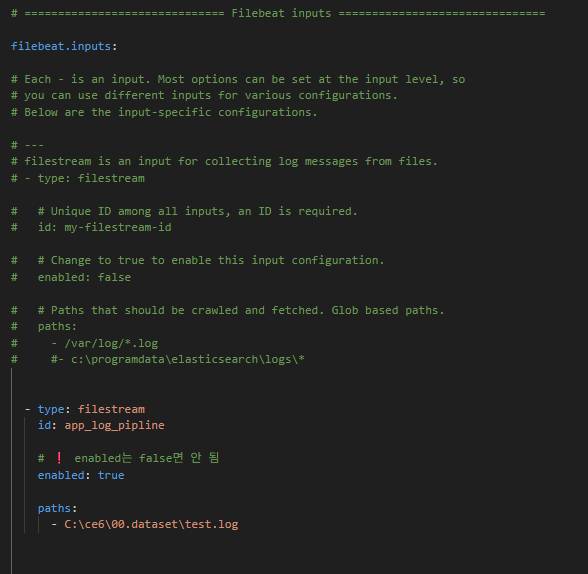
3.filebeat.yml설정을 합니다.


4. logstash config파일을 작성합니다

아 참고로 비번 추가해야해요엘라스틱
5. filebeat .exe실행 / logstash실행


6. 결과
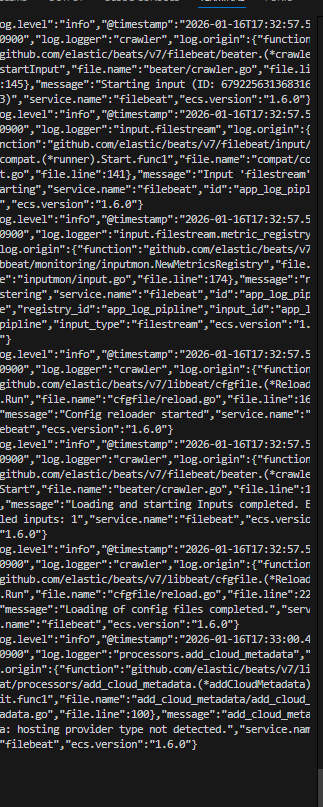

커맨드에는 잘 돼요
그리고
1️⃣ Logstash 먼저 시작 ← 수신자부터!
2️⃣ Filebeat 시작 ← 송신자
3️⃣ 로그 생성 시작 ← 데이터 발생
로그스태쉬먼저실행해야한대요

엘라스틱에도 잘 적재가 된 모습
https://github.com/seajihey/logPipeline/blob/main/README.md